
Anticiper les besoins en consommation électrique et les émissions de gaz à effet de serre des propriétés non résidentielles de SeattleTemps de lecture : 6 mins

La ville de Seattle souhaite devenir une ville neutre en émissions de carbone d’ici à 2050. Pour y parvenir, il est nécessaire de pouvoir anticiper les besoins en énergie des bâtiments de la ville et la pollution atmosphérique qui leur est associée. Cependant, les relevés sont couteux à réaliser.
C’est pourquoi, ce projet cherche à élaborer un modèle capable de prédire la consommation totale d’énergie et les émissions de gaz à effet de serre des bâtiments non résidentiels pour lesquels ces valeurs n’ont pas encore été mesurées, en se basant notamment sur leurs données structurelles et les relevés de 2016.
De plus, le score Energy Star est fastidieux à calculer avec l’approche utilisée actuellement. Son intérêt pour améliorer les performances de prédiction est aussi évalué dans ce projet.
Ce projet est orienté Machine Learning (ML) supervisé et se divise en deux parties :
- L’analyse exploratoire des données (EDA) pour découvrir les variables pertinentes à la résolution de la problématique métier et à la construction de nouvelles lors de l’étape de feature engineering, notamment au cours de laquelle les variables catégorielles sont numérisées sans recours à l’encodage One-Hot.
Les variables sélectionnées et créées sont nettoyées et complétées lorsque nécessaire tout au long de cette étape.
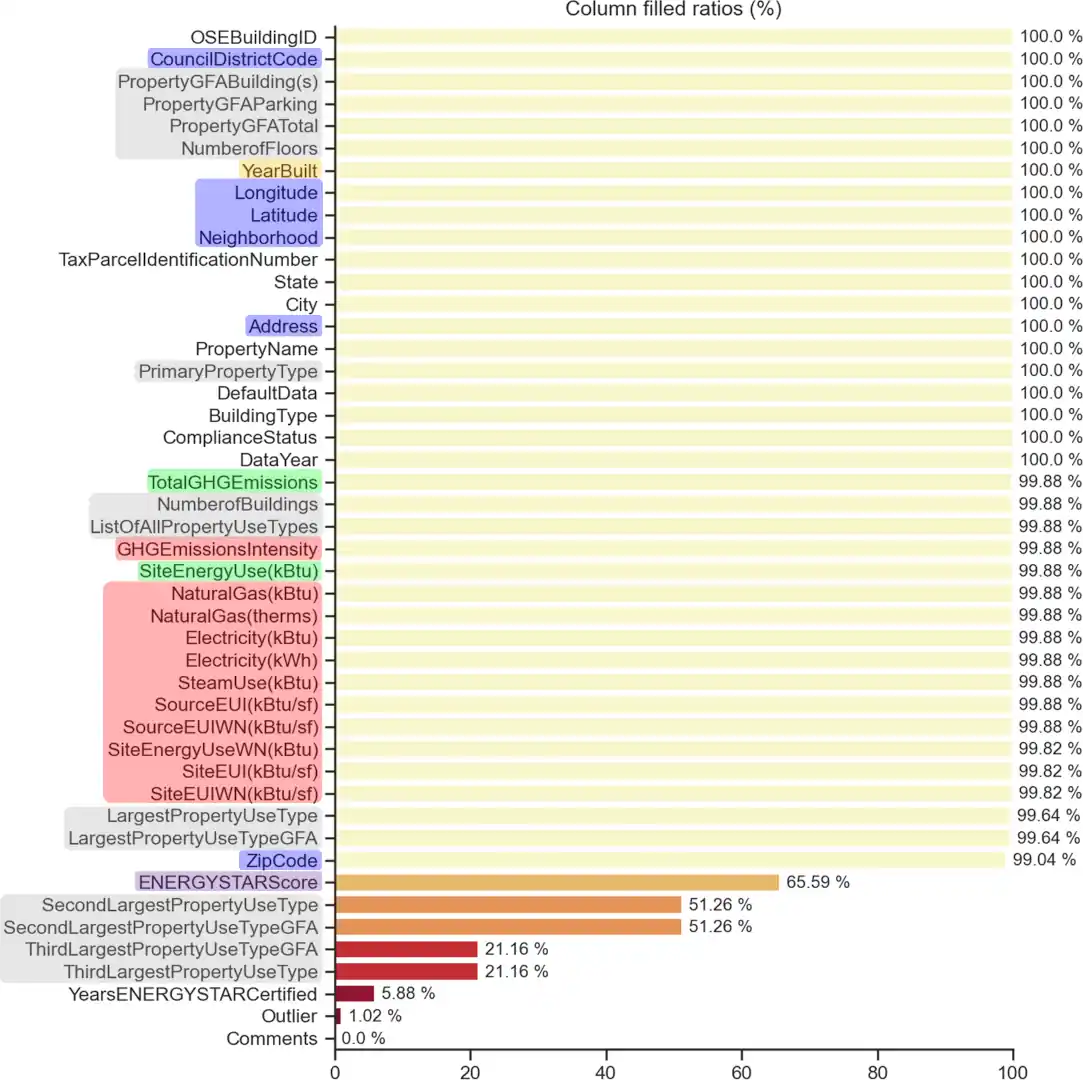



- Une fois le jeu de données prêt, la disparité de consommation et d’émission de gaz à effet de serre entre les propriétés étant de plusieurs ordres de grandeurs (un facteur de x1000 pour certains) les données sont passées à l’échelle logarithmique puis normalisées avant d’être utilisées par les modèles.
Ensuite, différents types d’algorithmes sont entraînés, optimisés, évalués par validation croisée et comparés sur leur capacité à prédire les deux variables définies précédemment pour sélectionner la solution la mieux adaptée à la problématique métier définie en début de projet.

Téléchargez le pdf du rapport de projet ou rendez-vous sur le dépôt GitHub pour plus de détails.
En conclusion, il apparaît que les modèles de régression linéaires ne sont pas adaptés à la résolution de notre problématique.
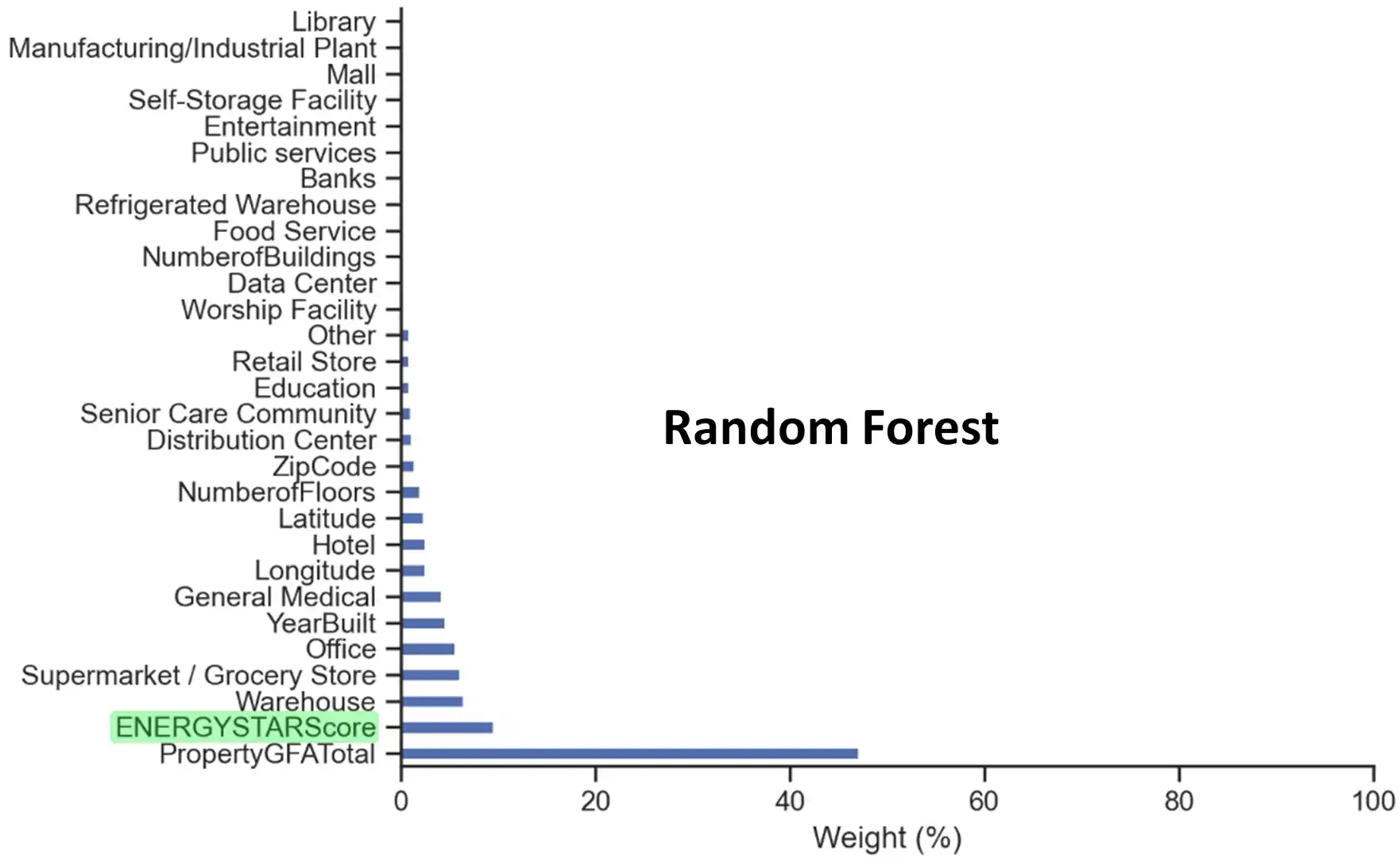
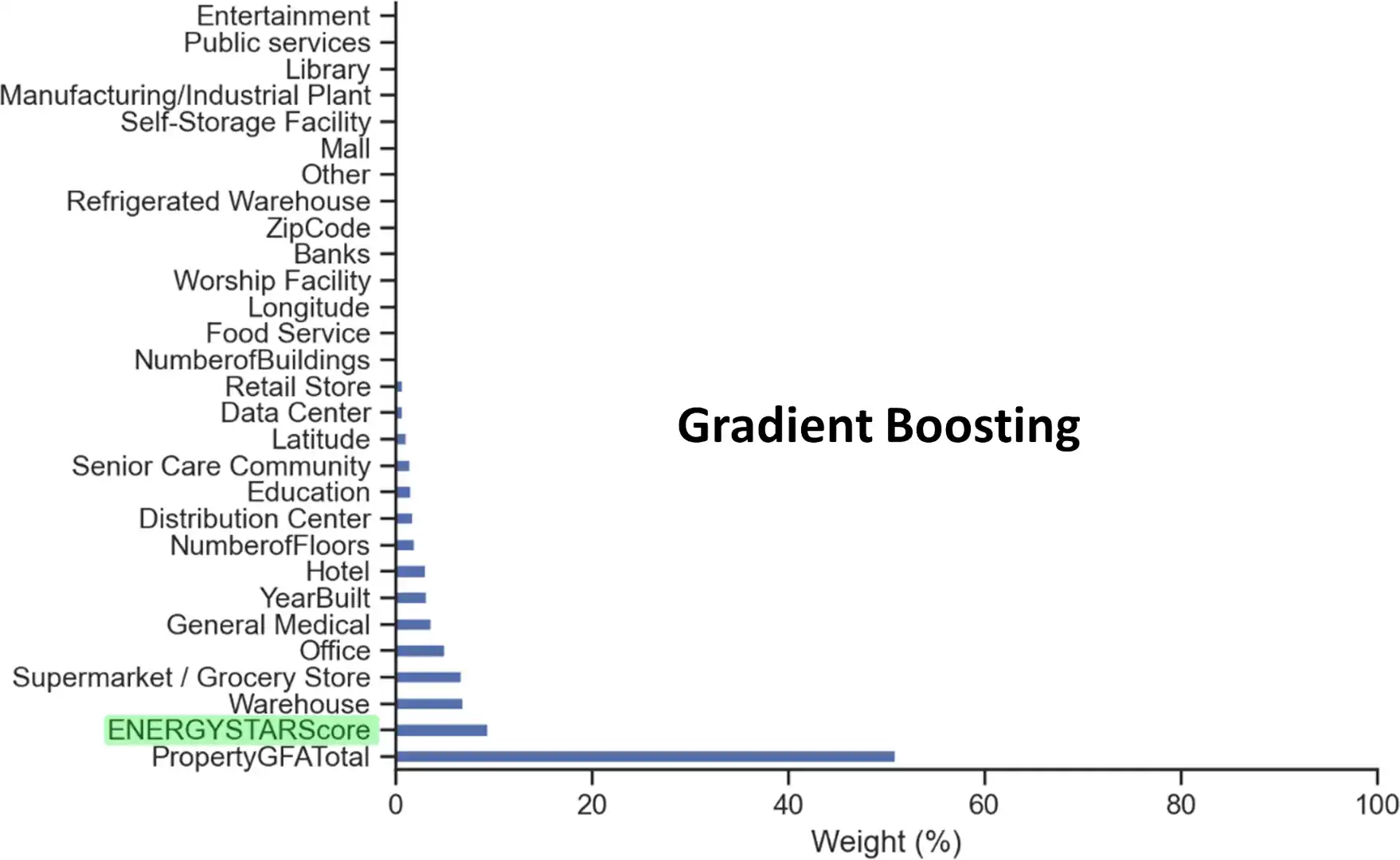
Malgré des performances comparables en termes de score et de généralisation, le gradient boosting se montre, la plupart du temps, sensiblement meilleur que la random forest et nettement plus rapide.
De plus, ce modèle est plus influencé par les données structurelles des bâtiments d’une propriété que son concurrent, le rendant plus adapté à répondre à notre problématique métier.
Enfin, au vu des résultats, le score Energy Star a clairement un effet positif significatif sur les performances des modèles dans les deux cas. Cependant, son établissement et son maintien ont un coût, notamment induit par la vérification par un professionnel agréé que les performances énergétiques et les conditions environnementales intérieures répondent aux normes de l’EPA. De plus, sur les seuls relevés de 2016, 35 % des propriétés de la ville n’ont pas cette certification et ne pourraient pas être prises en compte par le modèle sans.
Ainsi, en l’état, l’emploi du score Energy Star n’est pas recommandé au vu des performances qu’il apporte par rapport au coût des prérequis qu’il demande et à la proportion de propriétés de la ville qui ne sont pas encore certifiées.
Pour améliorer les performances de prédiction, il serait intéressant de tester d’autres modèles de types boosting comme XGBoost ou AdaBoost, voire de combiner plusieurs régresseurs différents (model stacking).
Compte tenu du nombre limité de propriétés ayant des valeurs singulières, il pourrait être intéressant de les traiter séparément en fixant un seuil, pour chacune des deux variables à prédire, au-delà duquel les propriétés seraient exclues du jeu de données. Ensuite, il faudrait évaluer si les performances de prédiction du modèle s’améliorent significativement, comparé au coût supplémentaire à traiter ces quelques propriétés indépendamment (relevés physiques toujours nécessaires pour ces propriétés).
Enfin, de façon plus générale, des choix différents lors du pré-traitement des données pourrait éventuellement amener des résultats différents vis-à-vis des performances de prédictions.