
Segmenter les clients d’un site e-commerceTemps de lecture : 8 mins

Olist, une entreprise brésilienne qui propose une solution de vente sur les marketplaces en ligne, souhaite fournir à ses équipes e-commerce une segmentation des clients de la plateforme qu’elles pourront utiliser pour leurs campagnes de communication.
La mission consiste à aider les équipes d’Olist à comprendre les différents types d’utilisateurs à travers leur comportement et leurs données personnelles pour différencier les clients en termes de satisfaction et de commandes, a minima, en regroupant les profils similaires.
Une proposition de contrat de maintenance basée sur une analyse de la stabilité des segments dans le temps est aussi attendue.
Ce projet est orienté Machine Learning (ML) non supervisé et se divise en 3 parties :
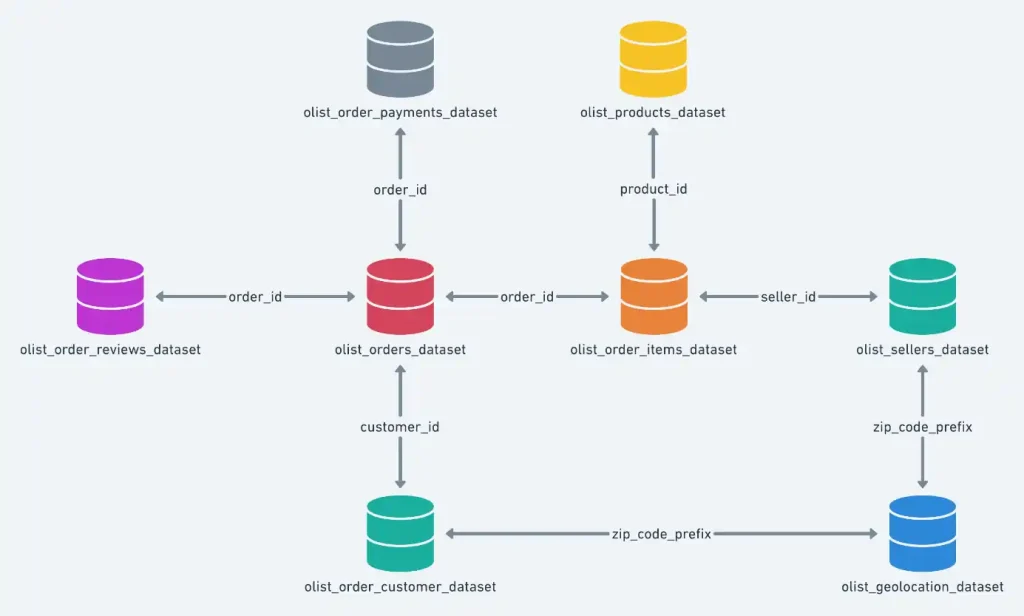
- L’entreprise stocke les données relatives à ses produits, ses clients, leurs commandes et leurs avis dans différents datasets reliés les uns aux autres par 1 à 4 features selon le jeu de données. Par conséquent, la première étape de ce projet consiste à déterminer dans quel(s) dataset(s) se trouvent les données relatives aux clients et aux commandes, puis à réfléchir à la manière la plus efficace de les agréger pour créer un unique dataset indexé sur les clients qui regroupe toutes leurs données.


- L’analyse exploratoire des données (EDA) prend place en même temps que leur agrégation et cherche à découvrir les variables pertinentes à la résolution de la problématique métier ainsi qu’à la construction de nouvelles lors de l’étape de feature engineering. À noter que les features ont été déterminées en priorité par la méthode RFM. L’ajout de variables pertinentes supplémentaires s’est ensuite fait en fonction des découvertes réalisées pendant l’EDA (voir le rapport du projet).
- NB : Les variables sélectionnées et créées sont nettoyées et complétées lorsque nécessaire tout au long de cette étape.
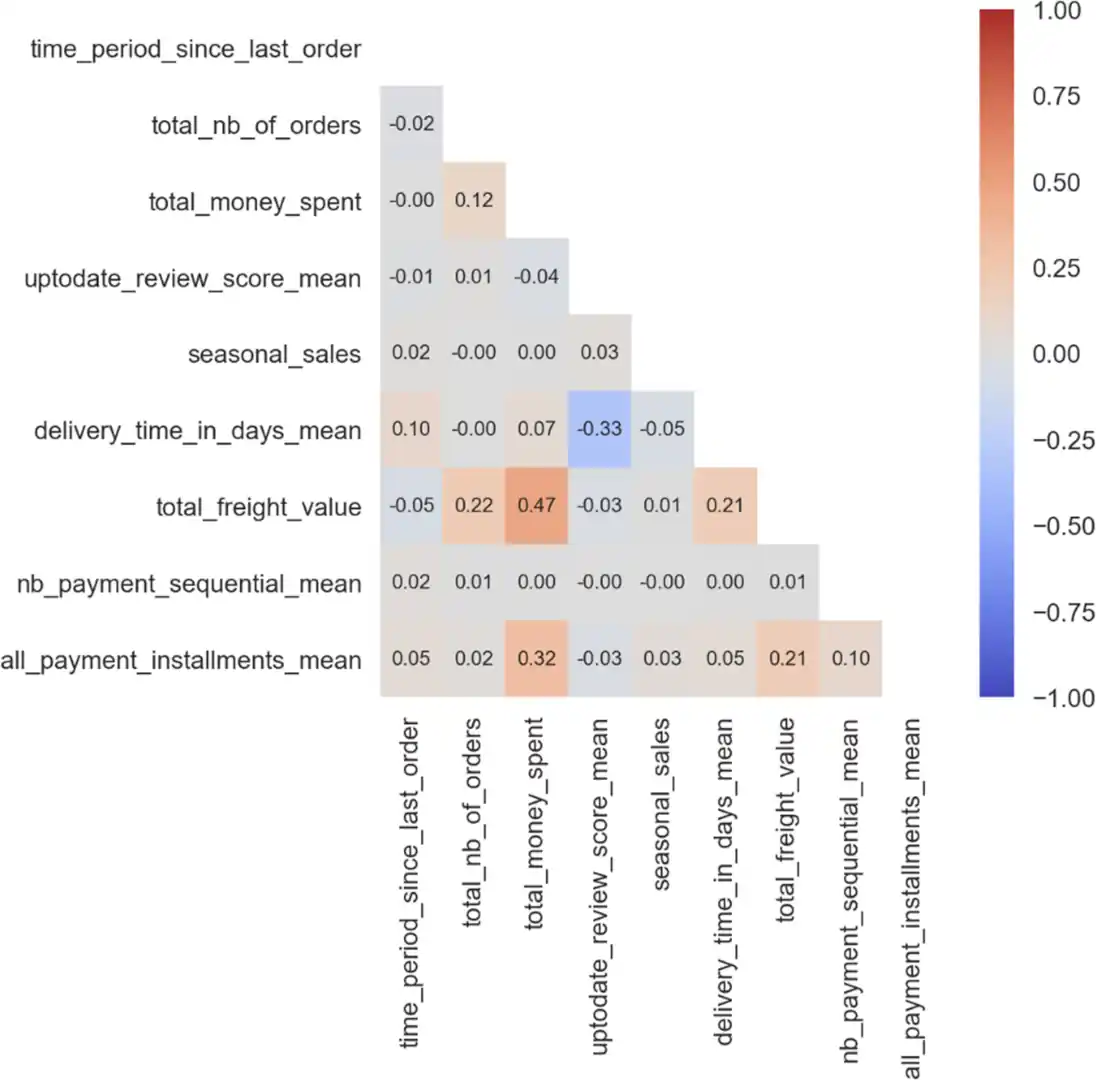
- Une fois le jeu de données prêt, la corrélation entre les différentes features est étudiée pour sélectionner un jeu de features suffisamment discriminant (indépendantes les unes des autres) afin d’aider les modèles de segmentation (clustering) à définir des catégories précises à partir des données fournies.
- Détermination du nombre de centroïds de départ par la méthode du coude sur le graphique de distorsion.
- Évaluation des performances de la segmentation par le score silhouette.
- Étude de stabilité à l’initialisation du clustering K-Means grâce aux scores ARI, AMI et d’homogénéité.
- 6 clusters obtenus avec une répartition des clients plutôt homogène.
- Optimisation des hyperparamètres epsilon et min_samples.
- 14 clusters obtenus avec notamment 2 clusters principaux comprenant 62 % des clients.
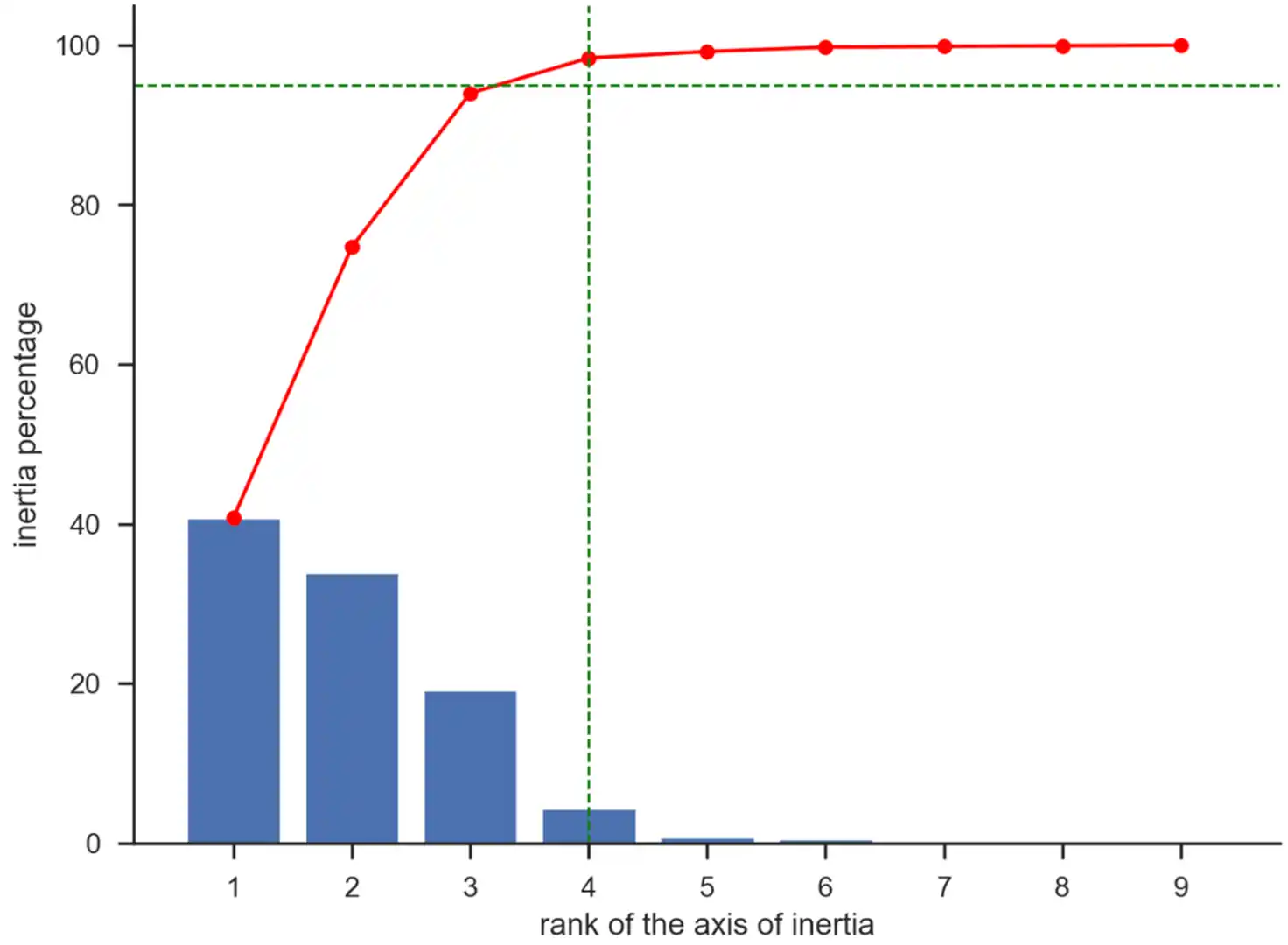


- Pour déterminer le temps nécessaire entre 2 segmentations et définir une période pour un contrat de maintenance, le dataset est découpé en plusieurs partitions en fonction des dates de commandes.
C’est l’étude de l’évolution du score ARI au cours du temps qui permet de déterminer la période de temps la plus optimale entre 2 segmentations du dataset.

Téléchargez le pdf du rapport de projet ou rendez-vous sur le dépôt GitHub pour plus de détails.
Modèles de segmentation
Au vu des résultats, la segmentation par K-Means semble plus adaptée à notre jeu de données. Le score ARI et la répartition des clients dans les différents clusters sont meilleurs qu’avec la segmentation DBSCAN.
Interprétation des clusters
Dans le cluster 0 ce sont des clients satisfaits. Ils sont livrés rapidement, ils préfèrent payer en une fois et ils peuvent être influencés par les ventes saisonnières.
Le cluster 1 représente des clients occasionnels et satisfaits, prêts à faire de petits achats tout au long de l’année avec de bons délais de livraison et des frais de transport réduits.
Le cluster 2 regroupe les clients mécontents qui connaissent des délais de livraison élevés et, la plupart du temps, ne passent qu’une seule commande. Malgré cela, ils sont prêts à passer de grosses commandes et préfèrent payer en plusieurs fois. Ils sont aussi très influencés par la saisonnalité des ventes.
Le cluster 3 semble très similaire au cluster 2. Les clients de ce cluster sont aussi mécontents avec des délais de livraison élevés. Ils sont aussi prêts à passer des commandes coûteuses, mais préfèrent payer en peu de versements et ils sont peu influencés par les ventes saisonnières.
Le cluster 4 rassemble les clients satisfaits, mais perdus qui aiment se sentir libres de payer par le moyen de leur choix.
Les clients du cluster 5 sont satisfaits, font des achats occasionnels et sont facilement influençables, mais ils pourraient être davantage fidélisés.
Période de maintenance
On peut définir une plage de maintenance après 2 mois pour commencer et à ce moment-là en redéfinir une autre qui pourrait éventuellement être plus longue cette fois, au vu de la cassure et du plateau que l’on peut observer à la suite des 2 premiers mois, selon les nouvelles données enregistrées d’ici là.
Une autre approche qui pourrait être intéressante serait la classification hiérarchique. La forte complexité spatiale et temporelle de cet algorithme force son utilisation à seulement un échantillon de peu d’individus. Toutefois, il est possible de l’utiliser à la suite d’une segmentation rapide (comme un K-Means, par exemple) dont le nombre de clusters formés est relativement important (50 ou 100) tout en restant négligeable face au nombre total d’individus. De cette façon, seul le haut de l’arbre (la partie la plus importante) est calculé, et le nombre d’individus pris en compte peut donc être plus grand.
Cette méthode permettrait de répartir les clients dans le nombre de clusters voulus après un seul processus de calculs. Sans avoir à réappliquer la segmentation à partir de zéro si l’on souhaite l’affiner ou au contraire réduire le nombre de clusters.
Il serait également possible d’ajouter de nouvelles features ou de modifier ou de remplacer certaines déjà utilisées pour essayer d’améliorer la segmentation afin d’obtenir des catégories encore mieux définies, plus facile à interpréter et plus en adéquation avec les différents profils de clients.
Enfin, de manière plus générale, des choix différents lors du prétraitement des données pourraient éventuellement amener des résultats différents vis-à-vis des résultats de la segmentation.