
Concevoir et déployer un modèle de « credit scoring »Temps de lecture : 11 mins

Le projet consiste à mettre en œuvre un outil de credit scoring pour calculer la probabilité qu’un client puisse rembourser le crédit qu’il demande et aider la société financière et les assurances à prendre leur décision lors du traitement de la demande de prêt. De plus, ce projet doit aussi répondre à une demande grandissante de transparence venant des clients concernant les décisions d’octroi de crédit.
- Cet outil doit permettre de définir la probabilité de défaut de remboursement d’un crédit sur la base d’informations relatives au client.
- Il doit également offrir un certain niveau de transparence et de simplicité concernant les données et leurs traitements en vue d’implémenter des méthodes d’interprétabilité du modèle sous la forme d’un dashboard interactif à destination des chargés de relation client ainsi que leurs clients.
- Une simulation du data drift est aussi réalisée en vue de déterminer une période de maintenance pour conserver des performances de prédictions optimales.
- Les données
- Adapter un kernel Kaggle pour agréger les données, générer les features pertinentes permettant de répondre à la problématique métier et réduire la dimension du dataset en sélectionnant les features les plus pertinentes à la réalisation du projet.
- Établissement d’un jeu d’entraînement, de validation et de test.
- Gestion du déséquilibre des classes pour l’entraînement du modèle :
- Techniques de rééchantillonnage.
- Attribution de poids.



- Méthode de classification
- Utilisation d’indicateurs techniques comme la sensibilité, la spécificité, la précision ou l’aire sous la courbe ROC (AUROC) pour mesurer la performance du modèle.
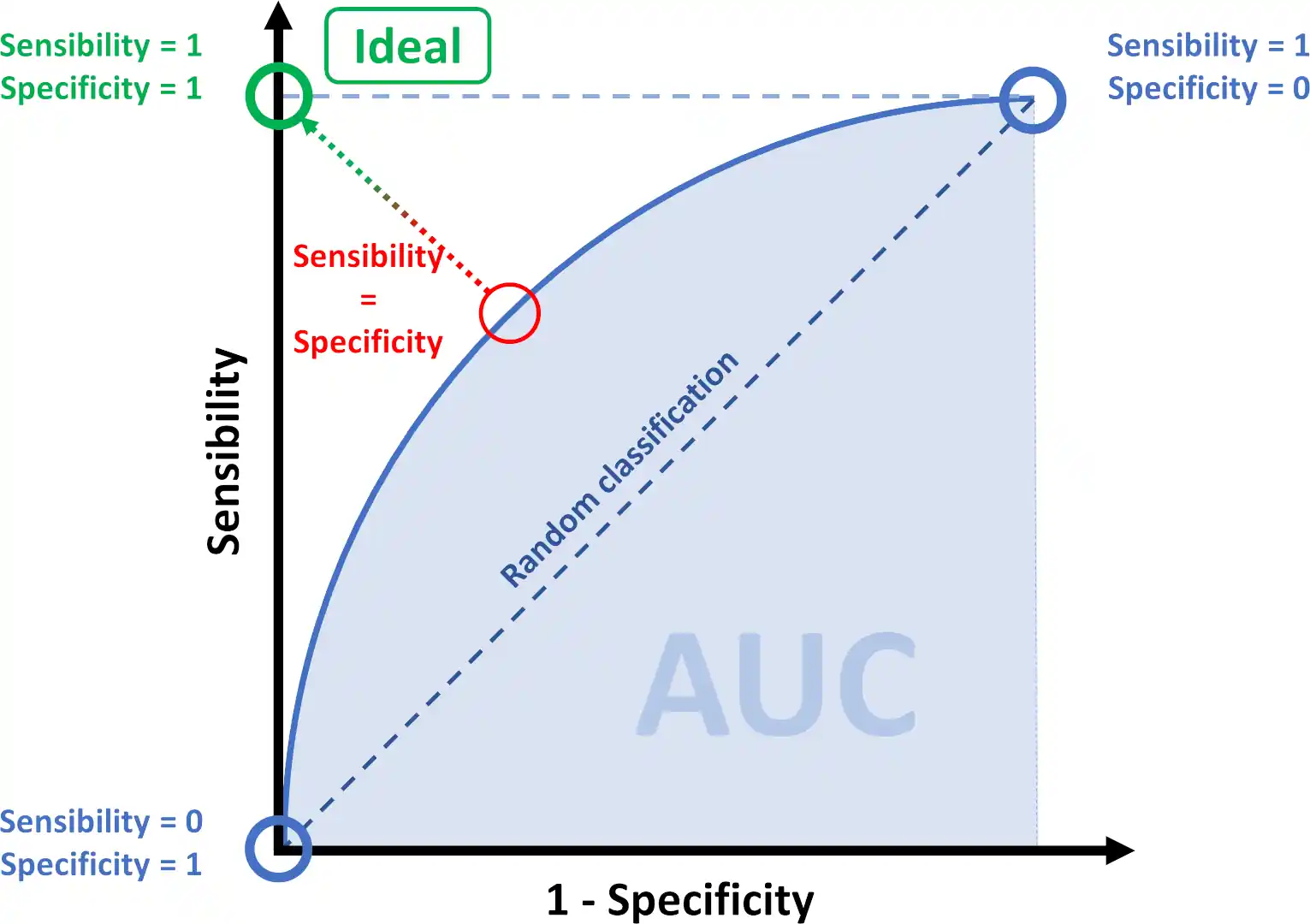
- Élaboration d’une fonction coût métier pour affiner les valeurs des paramètres du modèle, déterminer la probabilité qu’un client a de rembourser le crédit qu’il demande et déterminer le seuil de confiance sur remboursement optimal qui permet de réduire au maximum les pertes financières dues aux clients jugés à tort solvable ou non.

- Modèle
- Construction d’un modèle :
- Capable de gérer des données déséquilibrées.
- Capable de gérer des données catégorielles encodées de façon ordinales.
- Avec un classifieur qui intègre des méthodes de classification binaires et qui est capable de traiter un nombre important de données dans un temps d’exécution raisonnable.
- Avec une complexité relativement faible pour qu’il reste interprétable. Notamment, dans le but d’être transparent avec les clients et permettre aux chargés de relation client d’interpréter les prédictions faites par le modèle.
- Pour répondre aux critères développés dans les points précédents, les classifieurs testés sont :
- Le dummy classifier comme ligne de base.
- La régression logistique.
- Les classifieurs ensemblistes : Random Forest, XGBoost et LightGBM.
- Les hyperparamètres des modèles sont d’abord optimisés par un RandomizedSearchCV(), puis ceux du modèle sélectionné sont optimisés plus finement au moyen d’un algorithme d’optimisation bayesien.
- Les modèles sont évalués par validation croisée.

- Le tracking de l’entraînement et de la validation et le stockage des modèles entraînés est réalisé grâce à MLFlow.
- Interprétabilité du modèle
- Étude de l’importance des features à la fois au niveau global (sur l’ensemble des clients) et local (pour un client spécifique) par la méthode SHAP (SHapley Additive exPlanations).
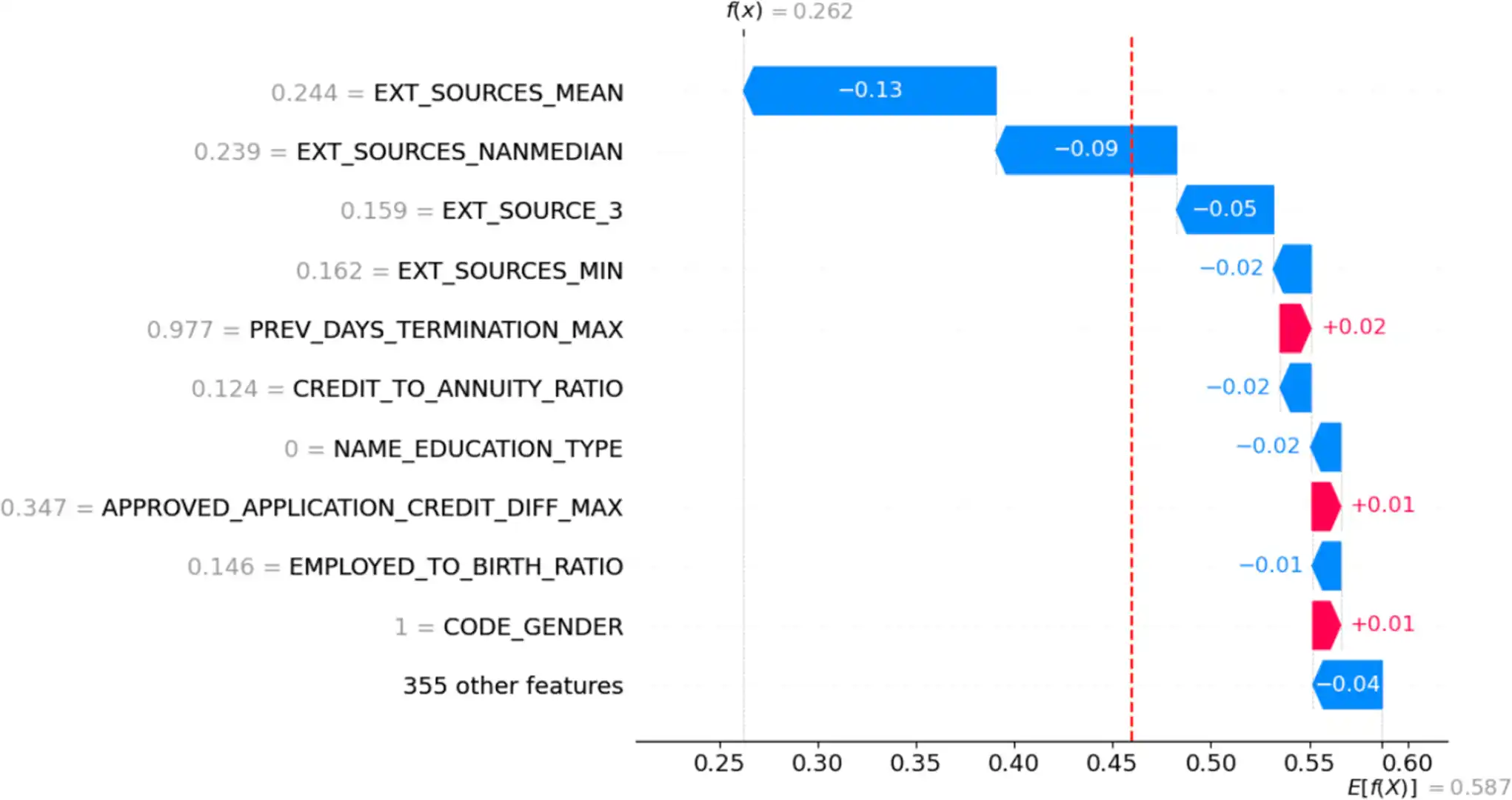
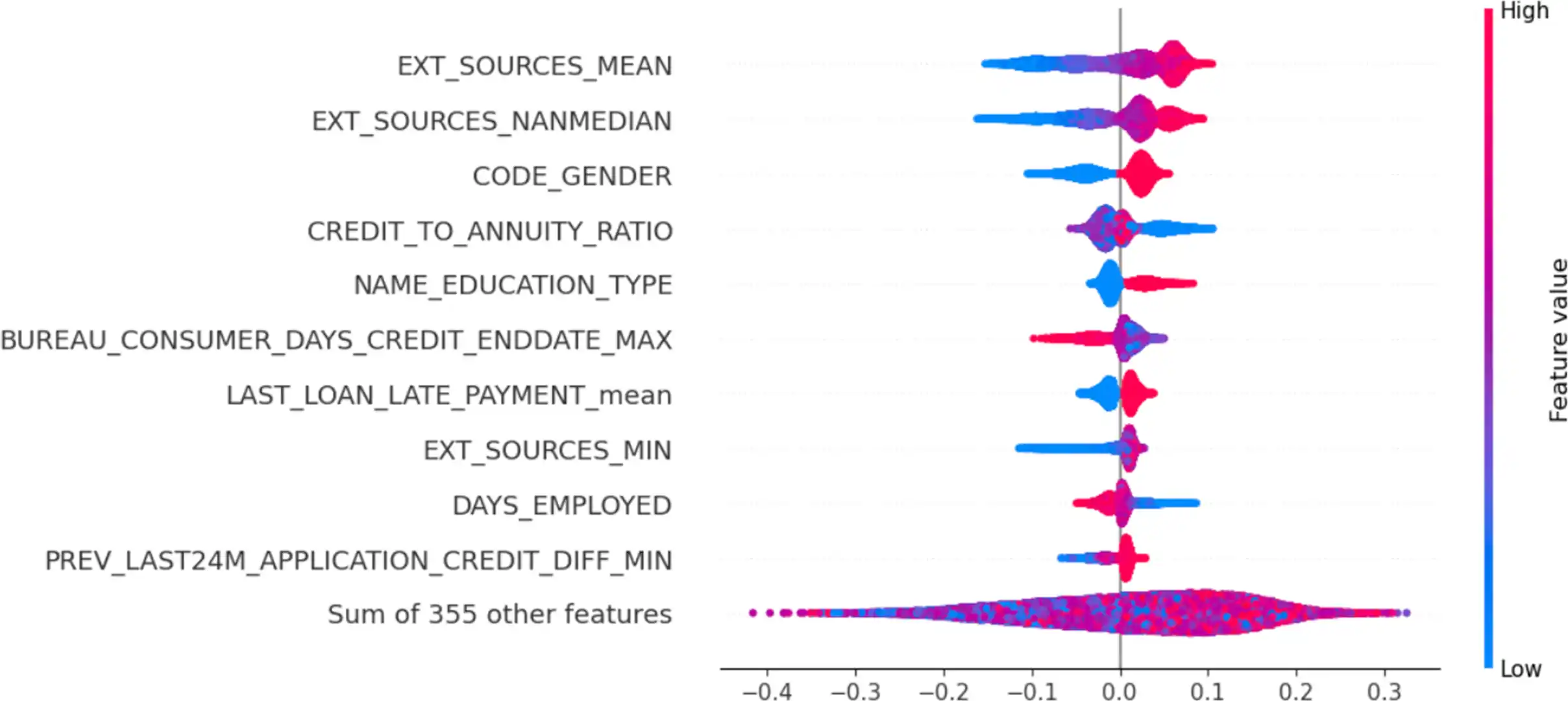
- Analyse de data drift
- Simulation du « data drift » dans le temps pour déterminer la période optimale de maintenance du modèle.

- Application
- L’application se décline en 2 parties distinctes déployées en ligne (hébergées sur Heroku) indépendamment l’une de l’autre :
- L’application backend a pour rôle de calculer et retourner le score du client sélectionné dans l’application frontend.
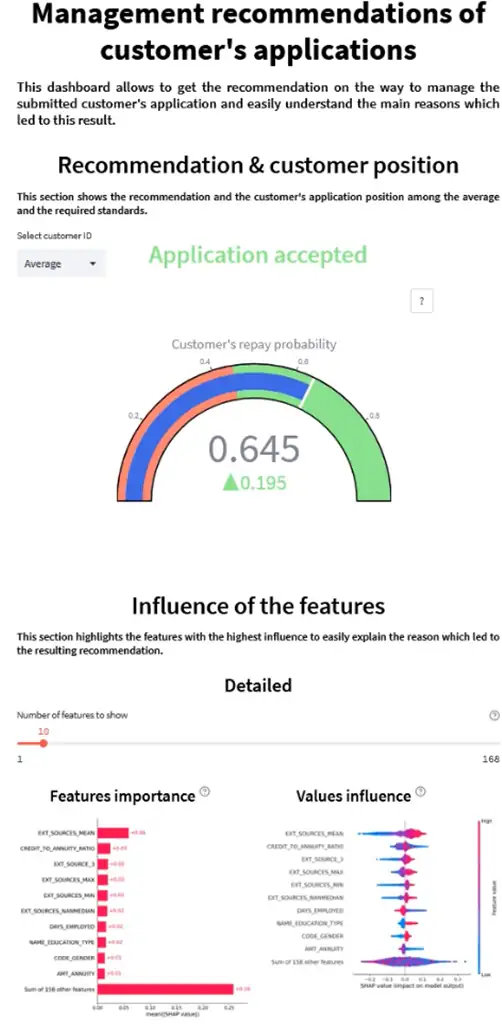
- L’application frontend prend la forme d’un dashboard interactif qui permet de sélectionner le client désiré par son ID et présenter le résultat retourné par le modèle à l’utilisateur de manière simple et interprétable.
Téléchargez le pdf du rapport de projet ou rendez-vous sur le dépôt GitHub pour plus de détails.
Modèle
Le classifieur LightGBM montre de bonnes performances dans toutes les situations, dont les meilleures lorsqu’associées à la méthode de cost-sensitive pour gérer le déséquilibre des classes, et répond à tous les critères de classification requis pour ce projet.
Bien que l’optimisation poussée des hyperparamètres n’a pas apporté d’amélioration significative des performances, le modèle généralise bien, quel que soit l’indicateur observé.
Data drift
D’après les résultats, il semble judicieux de fixer une première date de maintenance entre la 6ᵉ et la 7ᵉ année correspondant à un drift global d’environ 25 %. Toutefois, une discussion avec les experts métier permettrait d’ajuster ou de confirmer cette échéance.
Dashboard interactif
La réalisation du modèle a nécessité la conception de nombreux blocs de transformation et de traitement des données dans son architecture (comme en attestent les multiples notebooks). Chacun fait appel à des méthodes paramétrables et les résultats sont dépendants des paramètres choisis.
Sélection des variables
Les informations disponibles relatives à l’importance des variables devraient être débattues avec les experts métier en vue de définir les stratégies techniques à tester dans les différents blocs concernés :
- Seuil des valeurs manquantes.
- Techniques d’imputation.
- Corrélations entre variables.
- Réduction de dimensions et seuil de variance.
Équilibrage des données
- Essayer d’autres techniques d’attribution des poids lors de l’apprentissage sensible aux coûts.
- L’équilibrage des données introduit des données artificielles potentiellement incohérentes dans le cas du suréchantillonnage ou retirer des données importantes dans celui du sous-échantillonnage. Des tests supplémentaires peuvent être réalisés en variant les algorithmes et leurs paramètres. Il est aussi possible de combiner les techniques de suréchantillonnage et de sous-échantillonnage pour combiner les avantages des 2.
Fonction coût métier
Communiquer les règles métier et les critères financiers relatifs aux pertes et profits permettrait d’affiner davantage la fonction d’évaluation du gain pour l’approcher encore plus des contraintes métier réelles.
Classifieurs et optimisation des hyperparamètres
Plusieurs classifieurs ont été testés avant de retenir LightGBM. Cependant, il est aussi possible d’en essayer d’autres ou d’en combiner plusieurs par stacking. L’empilement de modèles peut améliorer les performances en combinant les avantages de chacun.
Pour encore affiner les performances du modèle, il est possible de continuer son optimisation avec davantage d’itérations sur l’algorithme d’Hyperopt ou d’ajouter davantage d’hyperparamètres, voire éventuellement, de sélectionner d’autres plages de valeurs pour les hyperparamètres testés.
Cependant, il est certainement plus prometteur de revenir sur l’EDA et le feature engineering afin de tester les performances du modèle sur d’autres choix d’imputation des valeurs manquantes ou de sélection et de pré-processing des features.
Interprétabilité du modèle
La méthode SHAP offre des résultats intéressants, en particulier pour l’interprétabilité locale. Par contre, son intégration dans une application front-end comme streamlit demeure assez mal prise en charge et demande souvent l’ajout de code, voire, l’import de bibliothèques supplémentaires non officielles pour compenser ce manque de compatibilité et afficher ses graphiques.
Concernant l’interprétabilité globale, les algorithmes basés sur les forêts aléatoires (mais également SHAP) permettent d’identifier les variables influentes. Cependant, d’autres approches comme les permutations de variables peuvent être testées pour valider ces résultats.
Dashboard interactif
- Séparer en 2 onglets différents l’application front-end avec :
- Les interprétations locales relatives aux clients sur le premier onglet.
- Les interprétations globales, plutôt destinées aux chargés de communication, avec des fonctionnalités supplémentaires comme la matrice de confusion ou la capacité de changer le seuil de classification à la volée pour observer l’évolution des résultats en direct pour un client ou l’ensemble d’entre eux, par exemple.
- Ajouter un panneau latéral affichant les caractéristiques propres au client (âge, genre…) pour en faciliter l’accès.
- Un discussion avec les experts métier permettrait d’améliorer la jauge de score en la divisant en zones de confiance adaptées à la banque et à ses clients.
Simulation du data drift
Discuter avec les experts métier et en apprendre davantage sur le coût monétaire d’une maintenance pour mieux adapter les seuils de drift de la simulation et définir une période de maintenance en adéquation.