
Déployer un modèle dans le cloudTemps de lecture : 6 mins

Ce projet s’inscrit comme première étape d’un projet plus global qui consiste à mettre à la disposition du grand public une application mobile permettant aux utilisateurs de prendre en photo un fruit et d’obtenir des informations le concernant. De cette façon, l’entreprise espère se faire connaître et attirer les investisseurs afin d’obtenir les ressources nécessaires à la réalisation de son objectif premier. En effet, « Fruit ! » s’est donnée pour mission de préserver la biodiversité des fruits par l’application de traitements spécifiques à chaque espèce grâce au développement de robots autonomes.
Ainsi, le projet présenté dans ce document consiste à développer dans un environnement Big Data une première chaîne de traitement des données qui comprendra le preprocessing des images de fruits de la jeune base de données suivi d’une étape de réduction de dimension. Le but étant de mettre en place les premières briques de traitement qui serviront lors du passage à l’échelle en termes de volume de données. Par conséquent, il n’est pas nécessaire d’entraîner un modèle pour le moment.
Ce projet m’a permis de me familiariser avec les outils cloud : Hadoop, PySpark et quelques services d’AWS. Il se divise principalement en 3 parties :
- Prise en main et complétion du travail effectué précédemment par un stagiaire en local.
- Choix du service cloud (AWS), configuration des outils requis (S3, EMR, rôle de service, tunnel SSH…) et déploiement du cluster d’instances EC2.
- Exécution du script dans le cloud, puis analyse du bon déroulement de la parallélisation des calculs.
- Mise en place de l’environnement local
- Mise en place d’une machine virtuelle Kubuntu avec VirtualBox.
- Installation de Hadoop pour exécuter le code PySpark en parallèle.
- Mise en place habituel de l’environnement python avec conda et pip.
- Les données
- Sélection du jeu de données et constitution d’un échantillon pour le développement du script en local (jeu de données constitué d’images).
- Élaboration du script
- Choix d’un modèle adapté au traitement d’images : MobileNetV2 (modèle de type CNN) dont le vecteur de sortie est de relativement faible dimensionnalité (1x1x1280).
- Choix de la méthode de transfer learning en préparation à l’entraînement du modèle à la suite du projet : Modèle pré-entraîné sur le jeu de données participatif ImageNet.
- Élaboration de la chaîne de traitement des images (4 étapes) :



- Présentation des résultats obtenus en local : Les partitions du dataframe final sont stockées au format parquet et contiennent les résultats des actions à chaque étape de transformation des images
- Création de l’environnement Big Data
- Choix du service cloud pour déployer le script dans un environnement rapide à configurer, stable et évolutif que l’on peut adapter suivant le volume de données à traiter de façon horizontale tout en maîtrisant précisément les coûts de mise en production.
- Élaboration de l’architecture cloud :
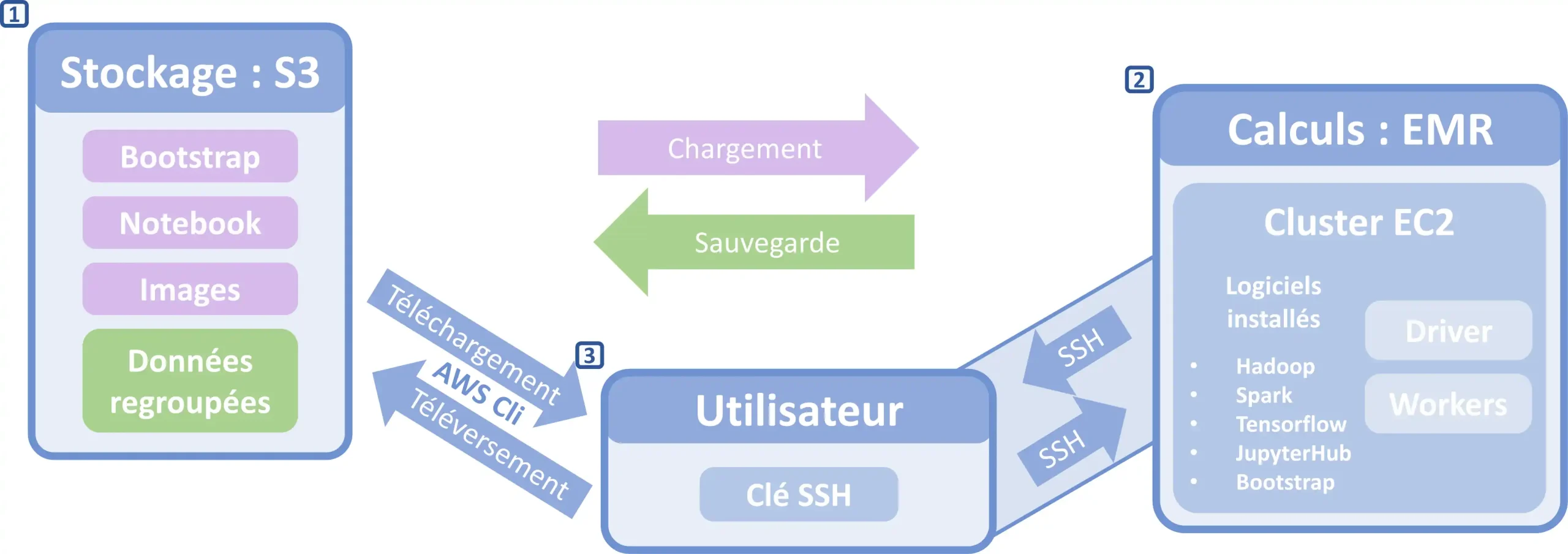
- Le serveur de stockage cloud Amazon S3 sur lequel sont téléversés tous les éléments nécessaires au fonctionnement de l’application ainsi que les sauvegardes des données obtenues après transformation.
- Les serveurs de calculs (ici des instances virtuelles) du cluster cloud Amazon EC2 encadrés par le service EMR à adapter selon la quantité de données à traité et les coûts.
- Au centre, l’utilisateur qui gère le stockage et donne les lignes directrices globales du travail à effectuer au cluster à partir de sa machine, par le biais de la console AWS Cli et au travers d’un tunnel SSH qui lui permet un accès direct aux logiciels installés sur le réseau du cluster.
- Déploiement et exécution dans le cloud
- Présentation des résultats obtenus après déploiement et exécution du script répartie sur plusieurs instances fonctionnant en parallèle dans le cloud.

- Exécution d’un test de mise à l’échelle horizontale.

Téléchargez le pdf du rapport de projet ou rendez-vous sur le dépôt GitHub pour plus de détails.
Dans ce projet, les fondations de la chaîne de traitement des images ont été développées en PySpark et exécutées dans le cloud au travers des services proposés par AWS.
Les images passent par une étape de preprocessing qui les adapte au modèle (MobileNetV2), pré-entraîné sur le jeu de données ImageNet (permettant de gagner en puissance, en temps de calcul et donc en coût), pour en extraire leurs features, réduites en dimension par ACP ensuite.
Ainsi, comme le montre les résultats des tests, les premières briques de traitement sont mises en place et prêtes à supporter une mise à l’échelle horizontale avec un jeu de données plus important, sur des serveurs situés au sein de l’union européennes (dans la zone géographique AWS de Paris) respectant les normes de la RGPD.